

When Patterson, Gibson, & Katz unveiled RAID in their 1988 paper, the demo proved that striping a row of cheap PC disks could outrun a $100k IBM 3380.
What it did not prove was survivability: one dead spindle and the whole array collapsed. The authors therefore pointed readers to a protection method that was already battle-hardened long before the word RAID existed—disk mirroring.
- 1970s: Tandem NonStop mainframes kept two identical drives on separate I/O paths so a single failure never halted the transaction stream.
- 1977: IBM patent (Ken Ouchi) described “shadow” copies on twin disks to guarantee data integrity.
- 1983: DEC HSC50 shipped RA8x subsystems with controller-level mirroring, the first commercial product that we would call RAID 1 today.
The Berkeley researchers simply formalized this practice as Level 1 in the new RAID taxonomy (or RAID 1), further pairing it with Level 0 (or RAID 0) striping to cover both performance and availability.
New to our series on servers and RAID arrays?
First, read our primer on "What Is RAID" to understand striping, mirroring, and parity—the three concepts on which all RAID levels are built.
With that foundation in place, let’s look at what the term RAID 1 really means, how it works under the covers, and why it became the de facto choice for data that must stay online even when a disk dies.
How RAID 1 Actually Works—Design, Mechanics, and Performance
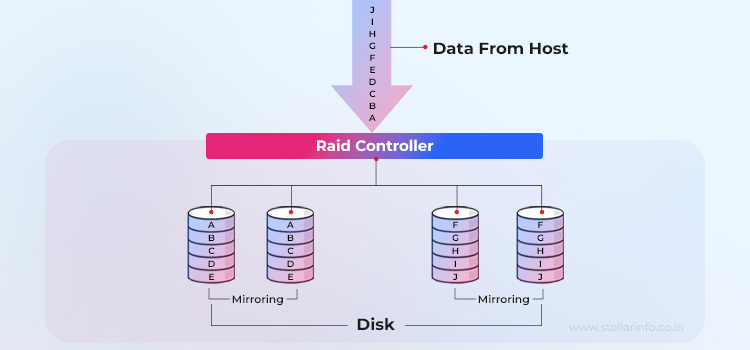
- The host’s I/O request arrives at the RAID controller. The server considers the whole array as a single logical disk and begins writing.
- The controller duplicates every write. Each block (A, B, C … in the diagram) is sent to both drives in the mirror set. This duplication is transparent to the host; no driver or application changes are required.
- Either disk can satisfy reads. For a read request, the controller may choose whichever member’s heads are closest, trimming seek time and, on smart HBAs (Host Bus Adapters), nearly doubling random-read IOPS (Input/Output Operations Per Second).
- If one drive fails, the controller simply continues using the surviving partner. Because the data is already complete on that disk, data loss impact is the lowest of all RAID levels—no parity math, no long rebuild window.
- When the failed drive is replaced (or a hot spare is present), the controller performs a sequential clone from the good disk to the new one, after which normal mirroring resumes.
So, RAID 1 is the canonical mirrored-pair configuration: every block the host writes is committed to two independent disks, producing two identical copies at all times. If either disk fails, the surviving partner continues to serve data without a hiccup. Because only one of each mirrored pair must stay healthy, the array’s fault tolerance is one drive per pair. However, the capacity is one-half of the raw total.
Usable GB = n×d / 2
where n is the number of drives and d is their individual capacity.
RAID 1: Write Path and Latency
In RAID 1, every host write is duplicated. The controller (hardware or software) issues two I/O commands and acknowledges completion only after the slower of the two disks reports success. Because the writes occur in parallel, end-to-end latency is essentially the same as a single disk; there is no extra seek or rotational delay beyond what each drive already incurs.
RAID 1: Read Path and Throughput
For reads, the RAID 1 controller can choose either disk.
Smart HBAs alternate requests in a round-robin or shortest-seek fashion, letting both heads work at once. When this load balancing is enabled, random-read IOPS can approach double that of a lone drive. However, simpler or older firmware treats the mirror as a single device and sees little or no boost.
RAID 1—Failure Handling, Hot Spares, and Rebuilds
- In RAID 1, when a disk goes offline, the virtual volume stays optimal; the controller simply reroutes all I/O to the surviving drive.
- If a hot spare (a disk drive on standby, ready to replace a failed drive) is present, it is claimed automatically and a background resync copies every block from the good member to the spare—no parity math, just a sequential clone.
- Rebuild time equals drive size divided by sustained transfer rate; with 4 TB SATA disks, that is a few hours.
In short, RAID 1 trades half of your raw capacity for the certainty that a single drive failure will never take data offline, while still letting well-tuned controllers squeeze almost RAID 0-class read performance.
However, in rare cases where both mirrored drives fail or the RAID controller is damaged, professional RAID data recovery services may be essential to restore mission-critical data.
Next we will weigh those benefits and costs against RAID 0 and the other classic levels.
Why Storage Solution Architects Pick RAID 1 (and Why They Don’t)
RAID 1’s single selling point is crystal clear: the array keeps running even if one drive dies. That resilience, however, comes at the price of capacity and (sometimes) write speed. Below is the practical balance you get when you trade striping-only RAID 0 for mirrored redundancy.
In the comparison table below, notice how RAID 1 jumps from “no stars” to a four-star rating for fault tolerance but falls to 50 % storage utilization—exactly half your raw terabytes.
| RAID level | Fault tolerance | Random performance | Sequential performance | Utilization |
| 0 | ★☆☆☆ | ★★★★☆ | ★★★★☆ | 100 % |
| 1 | ★★★★ | ★★★☆☆ | ★★☆☆☆ | 50 % |
The Net Benefits of RAID 1
- Always-on availability: A single failure is a non-event; users never notice.
- Predictable rebuilds: Resync is just a straight copy; 4 TB on 200 MB/s SATA finishes in ~6h—not days.
- Read acceleration: With a smart controller, random-read IOPS can reach nearly 2 × a single drive’s rate because either head can satisfy each request.
The Unavoidable Trade-Offs
- 50% of your raw capacity disappears—mirrored data is, by definition, paid for twice.
- Write performance equals the slowest member; every commit waits for two disks.
- Cost per protected terabyte is highest among the standard levels.
- Still Not a Backup: Corruption, ransomware, or accidental deletes are mirrored instantly; you still need snapshots or off-site copies.
RAID 1, therefore, occupies a very specific sweet spot: small-to-moderate datasets whose value dwarfs their raw capacity cost and workloads where read speed and continuous uptime matter more than write throughput.
RAID 1—Deployment Scenarios and Limitations
RAID 1’s sweet spot is any workload whose business value dwarfs raw capacity cost and where downtime is intolerable. Because every block is instantly duplicated, a mirror absorbs a disk failure with zero interruption and almost no performance hit.
Ideal Deployments
- Operating-system & hypervisor boot volumes: Even a brief outage can strand tens of VMs; vendors such as Oracle advise hardware RAID 1 for the system LUN on x86 and SPARC servers.
- Database redo/journal logs: Latency matters more than capacity, and logs must survive a crash so the engine can roll forward cleanly.
- Small but irreplaceable NAS shares: Photo libraries, office files, home-lab VMs, etc.
- Read-heavy reporting or web caches: Smart HBAs can service parallel reads from both members, delivering nearly 2× the random-read IOPS of a single drive while sustaining 99.999 % availability.
- Single-device NVMe nodes: Cloud providers still recommend a mirrored pair to protect against sudden SSD failure when no parity pool exists.
Scenarios to Avoid
- Petabyte-scale archives or video libraries: Mirrors burn 50% of every terabyte; erasure-coded or parity arrays cut the protection overhead to 20–33%.
- Write-intensive analytics: Each logical write becomes two physical writes, halving backend IOPS; parity RAID or RAID 10 offers a better $/write ratio at scale.
- Cold-storage tiers where every dollar/GB counts: Hardware costs double versus RAID 5/6, yet the availability requirement is often met with online replicas or off-site backups.
In short, RAID 1 is the insurance policy for small-to-medium datasets whose loss is unacceptable and whose access pattern is heavy on reads. When capacity efficiency or write throughput rules the day, mirrors give way to nested RAID 10, parity stripes, or object-store erasure codes.
Beyond the Simple Mirror—What Comes After RAID 1?
RAID 1 solved the single-disk-failure problem, but larger arrays soon demanded more bandwidth per spindle or more than one failure’s worth of insurance. Vendors and open-source kernels therefore blended mirroring with striping and, later, rearranged mirrors inside bigger, self-healing layouts.
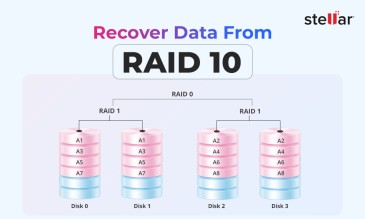
One example is striped mirrors, or RAID 10 (a.k.a. RAID 1 + 0). Take several mirrored pairs, then stripe across those pairs. Reads and writes are load-balanced across every mirror, so performance scales almost linearly with the number of pairs, while any single-disk failure—and often multiple, so long as the victims sit in different pairs—leaves the volume online.
Mirrored sets—whether classic RAID 1 or striped mirrors (RAID 10)—are still unrivaled for instant failover and predictable latency. Yet they burn half of every terabyte and still protect only against hardware loss.
The next leap was to keep the striping speed but replace whole-block copies with mathematical parity, cutting overhead to 20–33% and tolerating two-drive or even node-wide failures. That story begins with RAID 5 and RAID 6.
Important Reminder
Even with RAID 1’s mirrored pairs, unexpected hardware faults, simultaneous disk failures, or controller malfunctions can put your data at serious risk. In such scenarios, Stellar Data Recovery offers expert RAID data recovery services to help retrieve critical information with utmost safety and confidentiality.
Explore Real Cases Where We Successfully Recovered RAID Data:


About The Author

Data Recovery Expert & Content Strategist