

Summary
- The defining feature of RAID 6 is its use of dual parity, which allows it to withstand the failure of up to two separate hard drives without any data loss.
- Dual parity in RAID 6 offers robust protection, but it comes at a cost. RAID 6 is significantly slower for write-intensive tasks due to the complex calculations required to compute both parity sets and manage data distribution.
- You will always lose the storage capacity of two drives for parity information, which makes RAID 6 less space-efficient than RAID 5.
- RAID 6 is ideal for large-scale archives, backup systems, and mission-critical applications where data availability and integrity are more important than write speed.
- Despite its high redundancy, RAID 6 does not protect against file corruption, accidental deletion, or catastrophic events. It must be paired with a reliable plan for backup and RAID 6 data recovery.
The RAID revolution kicked off in 1988 when the idea of “redundant array of inexpensive disks” was explained in the paper presented by David A. Patterson, Garth Gibson, and Randy H. Katz at the 1988 SIGMOD Conference. The research paper also laid out five different RAID configurations based on mirroring, error correction, parity, parallelism (striping), and distributed parity.
For years, RAID 5—the highest RAID level described in the 1988 paper—was the go-to standard, as it offered single-drive protection without wasting too much capacity.
In our guide on RAID 5, we explained how a single parity block lets the array recover from one disk failure at the cost of extra write cycles.
But as hard drives grew from megabytes to terabytes, a dangerous weakness emerged. The problem was “rebuild time.”
Let’s understand the “rebuild time” constraint of RAID 5.
- Rebuilding a failed disk in a large RAID 5 array would stretch into days.
- Throughout that heavy I/O period, the surviving drives ran under extreme stress.
- If a second disk gave out before the rebuild finished, the array faced a total RAID failure—and all data vanished.
So, the storage world needed a stronger safety net. This need led to the emergence of an improvement over RAID 5, and it was called RAID 6.
What Is RAID 6?
According to the Storage Networking Industry Association (SNIA), RAID 6 is “any form of RAID that can continue to execute read and write requests to all of a RAID array’s virtual disks in the presence of any two concurrent disk failures.” In practice, it builds on RAID 5 by adding a second, independent parity stream.
This design goal is simple but important, as it allows RAID 6 to:
- Survive any two simultaneous drive failures.
- Keep data accessible even if another disk dies mid-rebuild.
These features make RAID 6 indispensable for large systems where data integrity is non-negotiable.
Design & Mechanics: How RAID 6 Works
The mechanics of RAID 6 can be broken down into striping and dual parity.
Striping
At its foundation, RAID 6 uses data striping. This means it takes your data, chops it into smaller chunks, and spreads (or "stripes") those chunks across multiple physical hard drives. This striping allows the array to read data from several disks at once, which is great for performance.
Dual Parity
The real value of RAID 6, however, is its dual-parity system. This system is best understood in the context of the single-parity system of RAID 5.
- RAID 5 (Single Parity): Each stripe stores one parity block computed by bitwise XOR of all data blocks. If one drive fails, the controller can rebuild its data by XOR-ing the remaining blocks and the parity block.
- RAID 6 (Dual Parity): Each stripe stores two parity blocks—P and Q. P is computed with XOR, and Q uses a Reed-Solomon algorithm over a Galois field. If up to two drives fail, the system solves two simultaneous equations (one for P, one for Q) to reconstruct both missing data blocks.
These parity blocks are rotated across all the drives in the array. This is done to prevent any single drive from becoming a bottleneck.
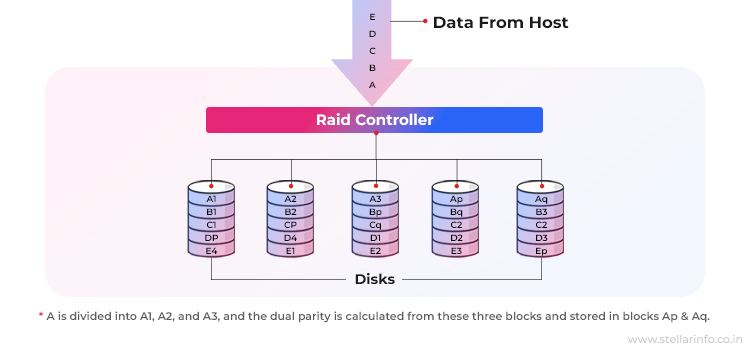
Note: At least four disks are required in a RAID 6 configuration: two for data and two for parity.
Read vs. Write Operations in RAID 6
The dual-parity design has a major impact on the write and read performance of RAID 6.
- Reading Data: Read operations are fast. The RAID controller knows where the data chunks are and simply reads them from the drives, ignoring the parity information. The performance is similar to other striped RAID levels.
- Writing Data: Write operations are much slower due to a process called a "read-modify-write" cycle. This process levies a significant write penalty on the array. To change even a small piece of data, the controller must perform six I/O operations:
- Read the old data block.
- Read the first old parity block (P).
- Read the second old parity block (Q).
- Write the new data block.
- Write the recalculated first parity block (P).
- Write the recalculated second parity block (Q).
This extra work is why RAID 6 isn't ideal for tasks with heavy, constant writing, like busy databases and surveillance systems.
RAID 6 Rebuild Process
When a drive fails in a RAID 6 configuration, the array enters a "degraded" state but remains online.
When you insert a new drive, the RAID 6 rebuild process begins.
- The controller reads all the data from the surviving drives.
- It also reads both sets of parity information.
- It then uses those mathematical rules in reverse to perfectly reconstruct everything that was on the failed drive onto the new one.
However, this process is long and puts the remaining drives under intense and prolonged stress. The greatest risk during this time is a RAID 6 rebuild error.
This failure happens if one of the surviving drives encounters an unrecoverable read error (a bad sector) while the controller is trying to read from it.
Since the controller can't get all the pieces it needs for its calculation, the rebuild can fail, and the array's data is put at critical risk.
RAID 6: Key Features & Performance Profile
| Metric | RAID 6 | Notes |
| Sequential Read | ≈ N × (single-disk bandwidth) | RAID 6 allows parallel reads from all data disks. |
| Sequential Write | ≈ (N – 2) × bandwidth – high write penalty | RAID 5 has one parity per stripe; RAID 6 has two, so each write costs six I/O operations. |
| Random Read IOPS | Near-linear scaling until controller/bus cap | Both RAID 5 & 6 distribute reads across disks with little overhead. |
| Random Write IOPS | ~⅙ of random-read IOPS (due to 6 I/O Read-Modify-Write operations) | Read-Modify-Write cycles multiply with parity streams. |
| Capacity Efficiency | (N – 2)/N usable space | RAID 6 sacrifices two disks’ worth for storing parity information. |
| Scalability | +1 disk → +1 × capacity; performance scales till limit is reached | More disks → longer rebuild; RAID 6 rebuild times are even higher than RAID 5’s. |
Comparison Between RAID 6, RAID 0, RAID 1, & RAID 5
| RAID Level | Fault Tolerance | Random Performance | Sequential Performance | Capacity Utilization |
| 0 | ★☆☆☆☆ (0 drives) | ★★★★☆ | ★★★★☆ | 100% |
| 1 | ★★★★☆ (1 drive) | ★★★☆☆ | ★★☆☆☆ | 50% |
| 5 | ★★★★☆ (1 drive) | ★★★☆☆ | ★★★★☆ | ≈ (N – 1) / N (≈ 80% for 5 drives) |
| 6 | ★★★★★ (2 drives) | ★★★☆☆ | ★★★★☆ | ≈ (N – 2) / N (≈ 67% for 6 drives) |
Advantages of RAID 6
RAID 6 delivers an advanced level of data protection with many key benefits.
- Enhanced Fault Tolerance: By storing two independent parity blocks per stripe, RAID 6 can survive the failure of any two drives simultaneously without downtime.
- High Data Availability: Continuous fault detection, healing, and write verification ensure that your volume remains online and consistent, even during rebuilds.
- Integrity for Large Arrays: If an array has 20–30+ disks, the odds of multiple failures rise sharply. RAID 6’s dual-parity design comes to the rescue and reduces the risk of total data loss.
- Balanced Read Performance: Read operations use all data disks in parallel for high throughput, as is the case in RAID 0.
- Built-in RAID 6 Failure Solutions: Should two disks die in a RAID 6 configuration, the RAID controller uses both the parity streams (P and Q) to reconstruct the lost data.
Limitations of RAID 6
Despite its robustness, RAID 6 comes with trade-offs that a storage admin must understand.
- Higher Write Penalty: Every write operation in RAID 6 triggers a sequence of six I/O operations (three reads + three writes). So, the write performance of RAID 6 lags behind that of RAID 5.
- Complex Dual-Parity Math: Computing both P and Q syndromes (the parity set) leads to higher CPU or ASIC overhead.
- Longer Rebuild Times: Two parity sets mean that if RAID 6 has to be rebuilt on multi-terabyte drives, the process can stretch from hours to days. This can expand the window for a RAID 6 rebuild error.
- Reduced Capacity Efficiency: Usable space in RAID 6 is (N – 2)/N, which is around 67% in a 6-drive RAID 6 configuration.
Together, these limitations mean that while RAID 6 excels in fault tolerance, it demands careful planning around performance and capacity.
When to Use RAID 6: Ideal Deployment Scenarios
RAID 6 works well in storage applications where data safety is much more important than pure speed or raw capacity. Some common use cases of RAID 6 are as follows.
- Mission-Critical Data Stores: When data loss is unacceptable, RAID 6’s dual-parity protection becomes unbeatable.
- Long-Term Archiving: RAID 6 delivers peace of mind in applications such as data archives, where integrity and retention matter more than write throughput.
- Large-Scale Arrays: In systems with 20+ drives, multiple failures become statistically likely. In such setups, RAID 6’s extra parity block acts as a crucial safeguard.
What Causes RAID 6 Failure
Even with dual parity, RAID 6 failure can still occur.
- Three (or more) disk failures: RAID 6 can survive up to two simultaneous drive losses. A third drive failure crosses that threshold and destroys the array.
- High Annual Failure Rates (AFR): RAID 6 use cases typically employ large batches of hard drives. When used in batches, hard drives tend to exhibit AFRs as high as 20–40%.
- Rebuild performance impact: Dual-parity reconstruction in RAID 6 taxes both spindles and actuators of HDDs and slows I/O operations. Because of this, storage admins can be tempted to postpone rebuilds.
- Complex parity math: Calculating P and Q syndromes demands more controller CPU/ASIC cycles. Under heavy load, this complexity can destabilize performance.
Together, these factors illustrate when and why a RAID 6 failure can overrun the array—and why proactive RAID 6 failure solutions are critical.
Is Data Recovery Possible After a RAID 6 Failure?
Yes. When your RAID 6 array malfunctions, knowing your recovery options can save the day.
- Within tolerance (1–2 drive losses): Native RAID 6 data recovery mechanism kicks in automatically. The controller uses the remaining data plus both parity streams to reconstruct missing blocks.
- Beyond tolerance (3+ drive losses): RAID 6 cannot self-heal. At this point, you need external measures such as off-site replication, snapshots, and professional data recovery.
For RAID 6 data recovery, it’s crucial to choose a service with proven expertise. The complex algorithms in RAID 6 require specialized knowledge and tools.
Stellar’s RAID recovery services can help because:
- Our engineers are experts in virtually reconstructing complex arrays, including the dual-parity schemes unique to RAID 6.
- We work on sector-level images of your drives, which ensures the original disks are never compromised during the recovery attempt.
- With certified cleanroom facilities, we can safely handle physically damaged drives and maximize the chances of a successful recovery.
In Conclusion
RAID 6 stands as a testament to engineering for a worst-case scenario. It deliberately sacrifices write performance and capacity efficiency for one clear goal—to keep your data safe against two simultaneous drive failures.
It's less of a performance tool and more of a robust insurance policy for your data.
So, choosing RAID 6 means you're prioritizing data survival above all else.
You may also find these related topics useful for a deeper understanding of RAID and data recovery:


About The Author

Data Recovery Expert & Content Strategist