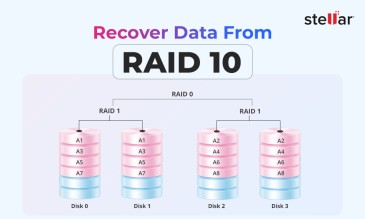


Summary
- A RAID server crash is a critical event and manifests as a system that won't boot, a missing volume, or constant reboots. All these events imply your data is immediately at risk.
- RAID crashes are caused by hardware failures like multiple dead drives, logical issues like a failed RAID configuration, or simple human error during RAID config and maintenance.
- After a RAID crash, do not attempt any unsafe DIY actions like re-initializing the array or running repair utilities, as these can permanently destroy your data.
- Your immediate protocol should be to power down the server, label every drive's exact position, and resist all prompts from the controller to rebuild or reconfigure.
- The only safe path forward after a RAID server crash is seeking the expertise of a professional RAID data recovery service.
A RAID server crash is every IT admin’s nightmare. It’s not just the commonplace “server won’t boot” issue; a crash can also mean:
- you suddenly see the system is stuck in a boot loop,
- your main data volume disappears, or
- the array becomes totally inaccessible.
Sometimes it may present itself as a blue screen, a red warning light, or the dreaded “no boot device found” message.
If any of these situations arise, your worries are not only restricted to downtime. There’s real risk of permanent data loss.
A RAID server crash is typically preceded by symptoms of a failing RAID array, but a crash can even hit suddenly without any obvious warning.
How you react now can make the difference between a complete rescue and total disaster. Let’s look at what causes a RAID server crash.
Why RAID Servers Crash: The Root Causes
A server crash is the result of a critical failure. Understanding the cause is key to recovery. These causes generally fall into three categories.

1. Hardware Failures
This is the most frequent reason for a sudden crash. A server hardware crash occurs when a physical component gives out without warning.
Multiple Drive Failures
A RAID array is designed to survive a single drive failure (or two, in RAID 6). But if a second drive fails before the first one is replaced and rebuilt, the entire array collapses.
RAID Controller Failure
The controller is the brain of your RAID. If it fails due to a power surge, overheating, or a firmware bug, the entire array becomes unreadable, even if the disks in the array are perfectly fine.
If you want to know more about how these failures occur and how data recovery experts fix them, explore our full guide on RAID Controller Failure.
Power Supply or Motherboard Issues
An unstable power supply or a motherboard failure can corrupt data as it's being written and lead to a crash.
2. Logical and Software Errors
Sometimes the hardware is healthy, but the software or configuration data that manages it gets corrupted.
Failed RAID Configuration
A mistake during a RAID migration or expansion can corrupt the array's metadata. This leaves you with a failed RAID configuration where the controller no longer knows how the data is distributed.
OS and Driver Updates
A bad operating system update or a faulty storage driver can create conflicts that make the RAID array inaccessible and trigger a system crash.
Virus or Malware
Malicious software can corrupt the file system or boot records and make the data unreadable.
3. Human Error and Environmental Factors
Improper Drive Replacement
Pulling the wrong drive from a degraded array or inserting drives in the wrong order during a rebuild can cause irreversible data corruption.
Sudden Power Loss
A power outage without a working UPS can cause a crash mid-write and can leave the file system and RAID parity in a corrupted state.
Overheating or Physical Damage
High ambient temperatures, dust buildup, or poor ventilation can cause drives and controllers to overheat or even physically warp.
Whatever the cause of a RAID server crash, the most important thing is not to take any step that could make things worse. In fact, most cases of permanent data loss happen because users aren’t aware of which actions are safe—and which are unsafe.
Mistakes to Avoid After a RAID Server Crash
The instinct to "try something" is powerful but dangerous. Common unsafe actions after a RAID server crash are as follows.
Do Not Re-Initialize the Array
Your controller might prompt you to "re-initialize" or "create a new array." Do not do this. This action erases the old RAID map and makes a professional RAID server crash recovery nearly impossible.
Do Not Run "Repair" Utilities
Built-in OS tools like CHKDSK are designed for single disks, not complex RAID arrays. When you run them on a failed array, you can end up scrambling data beyond repair.
Do Not Shuffle or Swap Disks
Guessing which disk has failed or changing their order can corrupt the data stripes that span across the drives.
Recommended First Actions After a RAID Server Crash
In a RAID server crash situation, a calm, methodical approach is everything. This is not the time for guesswork. Follow this protocol for RAID crash troubleshooting to give your data the best possible chance.
1. Power Down the Server Cleanly
Keeping the server running can trigger the OS or RAID controller to start automated "repair" attempts. These processes can write new, damaging data to your already fragile array. This can turn a recoverable situation into a permanent data loss scenario.
So your first and most important action is to shut the server down. If you can, use the operating system's shutdown command. If the system is completely frozen, a press-and-hold shutdown is the last resort.
2. Label Drives, Note Slot Order, and Take Photos
RAID data is striped across disks in a specific sequence. If this order is mixed up during a recovery attempt, the data will be reassembled as corrupted gibberish.
So, before you unplug anything, grab a marker. Label each hard drive with the exact slot number it came from (e.g., Disk 0, Disk 1, etc.). Then, use your phone to take clear photos of the drive bay, the labels, and the cable connections on the back.
3. Record Controller and Firmware Details
The controller's model and firmware determine the specific algorithm used to write data across the disks. This information is vital for data recovery engineers to accurately reconstruct the array's "map."
If you can, access the server's startup screen (BIOS/UEFI) or the RAID controller's own configuration utility during boot. Write down the exact model of the RAID controller (e.g., Dell PERC H730, HP Smart Array P420i) and its firmware version.
4. DO NOT Re-Initialize or Import a "Foreign" Configuration
Your RAID utility will almost certainly detect a problem and offer seemingly helpful solutions like "Initialize Disks," "Delete Array," or "Import Foreign Configuration." Do not select any of these options.
Initializing erases the array's metadata, which is the blueprint for your data. "Importing" a foreign configuration can overwrite this blueprint with incorrect information. So, resisting these prompts is one of the most important things you can do.
5. Check Boot Order, But Do Not Attempt a Rebuild
It’s safe to enter the BIOS/UEFI to confirm that the system is trying to boot from the correct device. However, if the RAID controller utility offers an option to "Start Rebuild" or "Force Online," do not use it.
A rebuild is a high-intensity process that writes new parity data to a disk. If you start a rebuild on the wrong disk or if another drive is on the verge of failing, the process will collapse and cause catastrophic data loss.
The Safe Path to Data Recovery From a Crashed RAID
When you’ve done all you can safely do, the next move is to call in Stellar RAID recovery. Our process begins with a direct call to a RAID Recovery Expert.
We’ll help you assess whether to keep the unit powered down, how to identify which drives need in-lab support, and explain how to pack your hardware for free and secure pickup.
The first step is to stop doing anything that could write new data to the disks.
At our ISO-certified Class 100 cleanroom, we image every drive with professional write-blockers before any recovery commands are run. This bit-for-bit copy protects your data against any accidental overwrites.
Our technicians then rebuild the RAID with the cloned hard drives by calculating parity bit movement and strip size parameters of the cloned HDDs.
If required, we also swap failed controllers from our donor library and repair physically damaged drives in our Class 100 cleanroom before creating the clones of the failed Hard drives.
Note: We support all major RAID systems with expert services like Dell Data Recovery, HPE Data Recovery, Synology Drive Data Recovery, QNAP NAS Data Recovery, NETGEAR Data Recovery, and more.
If you’d like to explore more about RAID levels and how they work, check out our detailed guides below:
FAQs
Replacing a disk only works for a degraded array. So if the array has already crashed due to multiple failures, simply adding a new disk won't work and can trigger a destructive rebuild. For safe RAID server crash recovery, experts at Stellar Data Recovery use specialized tools to rebuild the array logically first.
Server repair focuses on getting the hardware working again, for instance by wiping disks and reinstalling the OS. Data recovery is a process focused exclusively on safely retrieving your files. A server hardware crash requires both, but data recovery must always come first.
While a RAID 5 is designed to survive only one drive failure, it doesn't always mean the data is permanently lost if two drives fail. In many cases, professional data recovery services near you can use advanced techniques to reconstruct the array and retrieve a significant portion of the lost data from the server.
No. A "foreign configuration" alert means the controller sees disks that don't match its saved configuration. If you import it, you can overwrite the correct array map and make your data unrecoverable. This is a critical situation that requires the assistance of a professional RAID data recovery service like Stellar.


About The Author

Data Recovery Expert & Content Strategist